
:quality(80)/p7i.vogel.de/wcms/b5/ad/b5ade2e50671d986cabb091cc33de39f/0127234511v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/2d/69/2d69b27f3f8f5f290f7ae2b3d9123b1b/0127206601v1.jpeg "Storage-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/94/d2/94d28e3faac411c22b54d80ea354d2e3/0124559320v1.jpeg "Die digitale Souveränität Europas ist spätestens seit der Wiederwahl von Donald aktueller denn je. (Bild: erstellt durch iTernity GmbH mit Canva)")
:quality(80)/p7i.vogel.de/wcms/cd/d6/cdd6fc25c704ffe9ab6afc24ec68725e/0130507132v1.jpeg "Backups spielen auch in kleinen und mittleren Unternehmen eine zentrale Rolle für Betriebskontinuität – nicht nur als reine Datensicherung, sondern als Voraussetzung für Stabilität im operativen Geschäft. (Bild: © BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/08/b9/08b906f0ef0c5ad843b0ce1a09335985/0130533152v1.jpeg "Jakob Østergaard, CTO bei Keepit: „Strukturierte Tests und geführte Wiederherstellungen machen Backups erst zu einer wiederholbaren, zuverlässigen Funktion.“ (Bild: Keepit)")
:quality(80)/p7i.vogel.de/wcms/92/fa/92fa56077ccd3ff878b6a85ce4de1d32/0130727055v1.jpeg "Everpure hat die mehrschichtige Sicherheitsarchitektur von Portworx Enterprise ausgebaut. (Bild: Everpure)")
:quality(80)/p7i.vogel.de/wcms/07/38/07382204cc163f3172de0a99dc5d6abf/0130936373v1.jpeg "Bei Hybrid-Storage-Systemen werden unterschiedliche Technologien wie HDD-Speicher, SSD-Systeme und auch Tape-Librarys kombiniert. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/2c/31/2c310e263bd5f3746b66eb0b0eb711dd/0130707872v1.jpeg "Sandisk vermarktet seine WM-Edition als Sammlerstücke des Fußballturniers. (Bild: Sandisk)")
:quality(80)/p7i.vogel.de/wcms/86/06/86068cee815dbb389250a7655f0d55d3/0130597756v1.jpeg "Selbstverständlich sind drehende Festplatten noch lange nicht tot. Dank Leil lassen sie sich sogar „aufbohren“, um noch besser mit ihren SSD-Konkurrenten mithalten zu können. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/c8/48c8f436d680ea980781cbd728c109c1/0129826847v1.jpeg "Mit SwissTransfer stellt der Schweizer Anbieter Infomaniak eine Datentransferlösung bis 50 GB bereit. (Bild: Joos – Infomaniak)")
:quality(80)/p7i.vogel.de/wcms/ac/fe/acfef93609c37a7ea61b1e3244dea967/0130620671v1.jpeg "In einer KI-getriebenen Umgebung muss sich die Perspektive von einer speicherzentrierten hin zu einer datenorientierten Betrachtung verschieben. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/81/488147108a520bc67dadbdf1c59178c7/0129710650v1.jpeg "SDelete verhindert, dass beim Datenlöschen frühere Dateiinhalte in nicht zugewiesenen Clustern verbleiben. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c1/81/c1811ad769ce2c6fe9e5bfb2c8775591/0130016264v1.jpeg "Die Public Cloud bleibt für Künstliche Intelligenz wichtig. Doch für produktionsnahe und sensible Anwendungen bevorzugen Unternehmen privatere Infrastrukturen. (Bild: © Deemerwha studio - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/68/ff/68ff1f86c3747efa69a932a2b29e2e6f/0130912670v1.jpeg "Für die DSX Data Storage Conference im Hotel „Scandic Frankfurt Museumsufer“ hatte das Organisationsteam der Vogel IT-Akademie ein topaktuelles Programm mit hochkarätigen Speakern und Experten zusammengestellt. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/b7/55/b75581013900f582f2200a2d53e23359/0130382558v1.jpeg "Die Swarm Appliance ist eine schlüsselfertige Lösung für Data-Protection, Archivierung und Datenaufbewahrung in Edge- und ROBO-Umgebungen. (Bild: DataCore)")
:quality(80)/p7i.vogel.de/wcms/bd/0a/bd0a232a32dc365e8e19c2ad5a2aeb43/0130082482v1.jpeg "In dieser Folge von „Speicherhungrig“ spricht Chefredakteur Dr. Jürgen Ehneß mit René Nitzinger, Lead Product Manager bei MailStore, darüber, wie Unternehmen ihre E-Mails rechtssicher archivieren – und welche Fallen sie dabei vermeiden sollten. (Bild: Vogel IT-Medien/Mailstore)")
:quality(80)/p7i.vogel.de/wcms/4a/37/4a3731ad57c47e87cfedcd5342b9a4da/0129713569v1.jpeg "Microsoft erforscht die Langzeitspeicherung von Daten auf einem Speichermedium aus Glas (Project Silica). (Bild: Microsoft / Ashworth Photography)")
:quality(80)/p7i.vogel.de/wcms/02/2f/022f4cf56715e098d0cfb1c97812038e/0130515238v1.jpeg "RAG-Modelle und KI-Agenten rücken das Thema Storage wieder in den Mittelpunkt. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/24/3e/243e149198de7d0ac862c3edc694bfe4/0130490930v1.jpeg "19. Deutscher Nachhaltigkeitspreis 2026: der begehrte Award für die Sieger.
(Bild: Frank Fendler)")
:quality(80)/p7i.vogel.de/wcms/f8/db/f8dbe2337659dd44bdf89efec6cfcf1a/0129529497v1.jpeg "Im Gegensatz zu DRAM oder SRAM werden Informationen im STT-MRAM magnetisch gespeichert. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/fe/18/fe181da82b3e76596f4d461a5920a33a/0129473576v1.jpeg "SATAe sollte die Lücke zwischen SATA- und PCIe-Schnittstellen schließen, wurde dann aber vom M.2-Standard abgelöst. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ca/3f/ca3f194f4553759bea537346bc9e3988/0129465088v1.jpeg "Git Large File Storage ermöglicht ein effizientes Management großer Binärdateien. (Bild: Midjourney / KI-generiert)")
:quality(80)/images.vogel.de/vogelonline/bdb/1552300/1552323/original.jpg "Cloud-Speicher für Einsteiger – Microsoft OneDrive zusammen mit macOS und iOS nutzen. (©georgejmclittle - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1644500/1644561/original.jpg "Online-Speicher bei Web.de und GMX: So funktioniert die Verwaltung. (© stokkete - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1641800/1641842/original.jpg "All-Flash-Arrays versprechen unschlagbar niedrige Latenzen. (© pozdeevvs - stock.adobe.com)")
Der De-facto Standard für den Internet-Speicher, Teil 2 1A-Transportsupport und -services zwischen alter und neuer Speicherwelt
Der Zuspruch zu Amazons Webservices wächst. Die Hilfestellung des Unternehmens für die Migration von kleinen bis sehr großen Datenbeständen ist granular gestaltet. Trotzdem sollten sich Anwender klar machen, dass 1 Cent pro Gigabyte für das preiswerteste Speicherangebot nicht billig ist.
Anbieter zum Thema
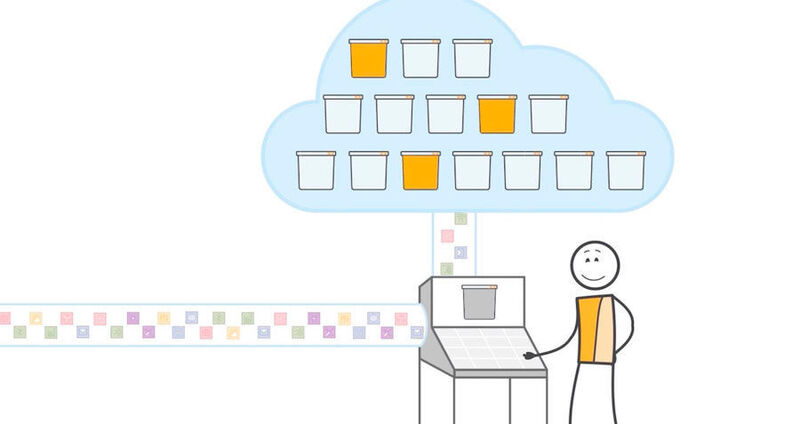
Eine weitere Option ist Reduced Redundancy, hier werden bei der zuverlässigen Vermeidung von Objektverlusten nur noch vier Neunen erreicht. „Dafür teilen wir aber im Falle eines Falles mit, welche Objekte verloren gehen“, sagt Gonzalez, so dass man sie aus anderen Quellen wieder restaurieren könne.
Seit 2012 archiviert AWS unter der Servicebezeichnung Glacier Daten in unbegrenzten Mengen auf unbegrenzt vielen virtuellen Bändern. Die Preise werden niedriger mit sinkender Zugriffsgeschwindigkeit – Glacier-Kapazität kostet nur einen Cent pro GByte und Monat.
Keine Datalakes, aber Objectbuckets
Was speichert AWS S3? Grundsätzlich alles. Allerdings gibt es, wenn bestimmte Funktionen angestrebt werden, Einschränkungen. S3 speichert Daten als Objekte in sogenannten Buckets (zu deutsch: Eimern), wobei ein Objekt bis zu 5 TByte groß sein kann – es passt also durchaus eine ganze Datenbank respektive Datenbanktabelle in ein solches Objekt, beispielsweise das Backup einer solchen.
In S3 erfolgt der Zugriff aber regelmäßig auf das gesamte Objekt – also auf das, was der Anwender als Objekt definiert und als solches auf den S3-Speicher geladen hat. Beim Datenbankzugriff will man aber regelmäßig nicht die gesamte Datenbank, sondern eben nur den Teil, der die Antwort auf die Suchabfrage enthält.
Hier rät das AWS-S3-Webforum eher zu AWS-Blockstorage (EBS).
Glück für AWS, dass die zukünftigen Datenmassen vorwiegend aus Objekten und anderen unstrukturierten Daten bestehen werden – man denke nur an die Massen von Bildern aus Video-Überwachungssystemen, Fotos, Audioaufnahmen, Messages von IoA (Internet of Anything)-Endgeräten und so weiter.
Speed und Sicherheit schließen sich nicht aus
Für mehr Speed und Skalierbarkeit hat AWS seine S3-Infrastruktur in Server, die Daten speichern, und Server, die lediglich S3-Schnittstellen handhaben, aufgeteilt. Wird mehr Kommunikationsvolumen benötigt, arbeiten mehr Schnittstellenserver, braucht man mehr Speichervolumen, wächst der Storage-Anteil der Infrastruktur. Das bewirkt, dass die Ein-/Ausgabe keinen Engpass mehr darstellt, woran Vor-Ort-Infrastrukturen nur allzu häufig kranken.
Sobald Objekte in S3 hochgeladen oder dort gelöscht werden, kann man Ereignisbenachrichtigungen über Amazon SNS (Push-Nachrichtenservice von Amazon) oder SQS (Messaging-Service von Amazon) verschicken lassen – zum Beispiel an AWS Lambda, um sofort Aktionen auszulösen, etwa einen bestimmten Workflow. AWS Lambda ist ein Datenverarbeitungsservice, durch den sich andere AWS-Services mit kundenspezifischer Logik anreichern lassen. Beispielsweise könnte man definieren, dass Mediendaten sofort beim Hochladen transkodiert werden.
Lebenszyklus-Management mit Compliance
Wer mehrere Versionen von Objekten hält, kann auf alle Versionen zugreifen und im Falle unbedachter Änderungen den vorherigen Zustand wieder herstellen. Allerdings kostet die Speicherung jeder Version etwas. Außerdem bietet S3 Funktionen für das Lebenszyklus-Management der Daten, beispielsweise können Nutzer Regeln für die Verschiebung von Speicherobjekten von einer Speicherklasse in eine andere festlegen, um die Kosten zu optimieren oder um Compliance-Regeln einzuhalten.
Auch die Sicherheit vor unbefugten Zugriffen spielt für AWS S3 eine wichtige Rolle. So werden die Daten beim Transport grundsätzlich SSL-verschlüsselt. Für die Verschlüsselung auf dem Server (Serverside Encryption, SSE) gibt es mehrere Varianten: Wählt der Kunde SSE-S3 überlässt er Amazon die Verschlüsselung und die Schlüsselverwaltung.
Bei SSE-C kommen die Schlüssel vom Kunden, die Verschlüsselung selbst übernimmt S3. Dabei braucht man für jedes Objekt einen Schlüssel, der diesem jeweils beim Upload hinzugefügt und nach der Speicherung des verschlüsselten Objekts gelöscht wird.
SSE-KMS bedeutet, dass S3 die Kundendaten mit Schlüsseln verschlüsselt, die vom AWS Key Management Service erzeugt wurden. In AWS KMS gibt es separate Berechtigungen für die Masterschlüssel. Zudem speichert die Lösung, wer wann welche Schlüssel für den Zugriff auf welche Objekte genutzt hat und wann fehlgeschlagene Versuche zum Objektzugriff durch wen durchgeführt wurden. Aktionen in S3 lassen sich über den Service CloudTrail verfolgen.
Mehrere Upload-Möglichkeiten
Wie kommen die Daten in S3? Dafür gibt es drei Möglichkeiten: Erstens lassen sich dafür die ohnehin vorhandenen Internet-Verbindungen benutzen, wobei auch keine zusätzlichen Kosten entstehen. Allerdings sind diese für größere Datenmengen, etwa im Terabyte-Bereich, zu langsam. Wenn es schneller gehen soll, stellt Amazon zwei Möglichkeiten bereit.
Zum einen Direct Connect: Darunter versteht AWS Direktverbindungen zwischen einer Kundenlokation und einem Amazon-Rechenzentrum. Sie lassen sich über VPN (Virtual Private Networking) nach 802.1q in mehrere separate logische Verbindungen auftrennen, über die Daten direkt in die vorgesehenen Buckets eingestellt werden.
Dabei stehen Verbindungsbandbreiten zwischen einem und zehn GBit/s zur Verfügung, die Portbandbreiten können von 50 MBit/s bis 10 GBit/s variieren. AWS empfiehlt Direct Connect, das in Europa zu den Rechenzentren Frankfurt und Irland möglich ist, bei großen Datensätzen, Echtzeitdaten-Feeds und für den Aufbau von Hybrid Clouds.
In letztgenanntem Anwendungsfall kann vom privaten Netzwerk eine VPN-Verbindung zu S3, aber auch zu einer oder mehreren Amazon Virtual Private Clouds (VPC) aufgebaut werden, die wiederum ihre Daten möglicherweise zum Teil in S3 speichern dürften. Wer eine AWS-VPC betreibt, kann diese so konfigurieren, dass sie direkt und sicher auf S3-Speicher zugreift. Man spricht hier von einem VPC-Endpunkt.
(ID:44067792)
:quality(80)/p7i.vogel.de/wcms/90/20/9020b592d980942aea690dff7b6316fd/0125836165v1.jpeg "Storage aus der Cloud: Online-Buchhändler Amazon bietet auch Speicherplatz an – wie den Objektspeicherservice S3. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e5/9f/e59f3f8430df38b89ea89b57fab9f504/0129017565v1.jpeg "TransferNow bietet eine umfassende Infrastruktur für den Austausch umfangreicher Datenmengen im privaten und geschäftlichen Umfeld, umgesetzt als europäische Lösung mit global verteilter Cloud-Infrastruktur. (Bild: Midjourney / KI-generiert)")