
:quality(80)/p7i.vogel.de/wcms/85/3c/853cb31461d6645416dd13e94644f9ff/0131873297v1.jpeg "Die ETERNUS AB-Familie mit dem Fokus auf All Flash und die ETERNUS HB-Familie als hybrides Storage-System. (Bild: Fsas Technologies)")
:quality(80)/p7i.vogel.de/wcms/b5/ad/b5ade2e50671d986cabb091cc33de39f/0127234511v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/2d/69/2d69b27f3f8f5f290f7ae2b3d9123b1b/0127206601v1.jpeg "Storage-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/ff/5b/ff5b58682271becaa4ac5af26e0c88a5/0131434597v1.jpeg "LINBIT DRBD spiegelt die Daten von Festplatten, Partitionen oder logischen Volumes zwischen zwei oder mehreren Hosts. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/85/ca/85caa4c3a57fc01317f2325f05bfed11/0131758836v1.jpeg "Everpure hat die Datensicherungslösung Portworx Backup 3.0.0 speziell für Service-Provider entwickelt. (Bild: Everpure)")
:quality(80)/p7i.vogel.de/wcms/cf/8a/cf8adcee248f68a1e2f0b465c9c37cf0/0130469152v1.jpeg "Datenresilienz bezeichnet ein ganzheitliches Konzept, das die sofortige Handlungsfähigkeit eines Unternehmens im Schadensfall garantiert. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f4/63/f463b2ba92d461500039f7837fe34bb7/0131753254v1.jpeg "Künstliche Intelligenz mischt mittlerweile auch bei der Formel 1 mit. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/84/9e/849eefd56240cc80fcfc5e31d532b5eb/0131159606v1.jpeg "Der KI-Boom hat zwiespältige Auswirkungen auf die Storage-Branche: Einerseits bringt er eine Nachfrage nach optimierten Systemen, andererseits treibt er die Preise nach oben. (Bild: © ALPSARAL - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/20/bf/20bf907841e2c20936821664dd3c8039/0131075905v1.jpeg "Das AccdbMerge-Tool vergleicht Inhalt und Aufbau mehrerer Access-Datenbanken. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/4b/6f/4b6f441d2c5b987b95cd8f006b45ee29/0131787054v2.jpeg "Acronis wächst über Backup und Security hinaus. Mit Cyber Frame bringt der Anbieter eine eigene Infrastrukturplattform für MSP. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/8a/6a/8a6a4bf1a520227e31daa4e8f59421ef/0131293145v1.jpeg "Welche Cloud-Services, die sich mit der Krone der Souveränität schmücken, sind tatsächlich souverän? Vier Fragen können entlarvend sein. (Bild: © Quensha - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/73/a3/73a38c6b825a6d80eaf53425c603c522/0131434411v1.jpeg "OpenEBS wurde für Kubernetes entwickelt und stellt dort Container-nativen Storage bereit. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5d/17/5d1796d4340bac85e90dc5827dd76511/0131063951v1.jpeg "Beim Datentransfer mit Smash werden alle relevanten Aktionen unkompliziert und direkt über die zentrale Eingabe gesteuert. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/4e/31/4e31cbf0807636f54ea7f6d60b7e5528/0131660732v1.jpeg "MailStore 26.2 steht ab sofort für alle Produktlinien zur Verfügung, einschließlich der Cloud-Variante und der Service Provider Edition. (Bild: MailStore)")
:quality(80)/p7i.vogel.de/wcms/99/b8/99b80de8dcbb3f9c1dc64e7e095c417c/0130967771v1.jpeg "LTFS ist ein Dateisystem für LTO-Bänder. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/04/cc/04ccc504aee183fd610969ddf31ebbc1/0130625872v1.jpeg "Für praktisch jeden Speicherzweck findet der geneigte Kunde auch passende europäische Angebote. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/6c/30/6c3087fd8e2e943e4d6214aa6cd2278f/0131596310v1.jpeg "Laut dem Synaxon Gehaltsspiegel 2026 sind die Gehälter bei IT-Dienstleistern in allen Support-Bereichen spürbar gestiegen. (Bild: Canva / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e7/8b/e78b629cfd54d655011f460479c989f0/0131648312v1.jpeg "Als Folge der aktuellen Chip- und RAM-Krise wird Hardware vom operativen Thema zur strategischen Stellschraube. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c5/5c/c55c680f89258f17536d78c4dbf7f1e6/0131380963v1.jpeg "Das OSD ist für die Verwaltung und Speicherung der Daten als Objekte auf dem physischen Speicherlaufwerk zuständig. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/59/06/5906e630fe8d3c185672c5e9f5fe6fc0/0131156502v1.jpeg "Ceph RADOS speichert sämtliche Daten in Form von Objekten. (Bild: Gemini / KI-generiert)")
:quality(80)/images.vogel.de/vogelonline/bdb/1552300/1552323/original.jpg "Cloud-Speicher für Einsteiger – Microsoft OneDrive zusammen mit macOS und iOS nutzen. (©georgejmclittle - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1644500/1644561/original.jpg "Online-Speicher bei Web.de und GMX: So funktioniert die Verwaltung. (© stokkete - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1641800/1641842/original.jpg "All-Flash-Arrays versprechen unschlagbar niedrige Latenzen. (© pozdeevvs - stock.adobe.com)")
Enterprise Search, Teil 2 Was eine Enterprise Search können sollte
Welche Faktoren zeichnen eine gute Enterprise Search-Lösung aus? Sie muss in der Lage sein, Unternehmenswebsites vollständig zu durchsuchen – einschließlich interner, nicht öffentlicher Dokumente - unter Berücksichtigung der Zugriffsrechte. Das geht nicht ohne die passende Architektur.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
Um dies zu gewährleisten, ist neben der On-demand Indexierung für neue Inhalte auch die Berücksichtigung der jeweiligen Zugriffsrechte, wie z. B. Access Control List (ACL), erforderlich. Zudem ist das Logging der Suchanfragen zwecks Reporting eine Grundvoraussetzung.
Wegen der individuellen Anforderungen, die Unternehmen an die Suche stellen, ist eine maßgeschneiderte Lösung zu empfehlen, die schnell zu integrieren ist – bei transparenten, überschaubaren Kosten. Zudem haben Firmen mit einer solchen Lösung die volle Kontrolle über geschäftskritische Informationen und können für optimalen Datenschutz sorgen.
Lucene stellt nur Kern einer Suche zur Verfügung
Viele Open Source-Lösungen basieren auf der Apache Lucene-Technik. Den Kern von Lucene bildet eine Programmbibliothek, die den Index aus digitalen Formaten generiert, bereitstellt und entsprechende Suchergebnisse liefert. 1999 erstmals veröffentlicht, wurde Lucene 2001 Teil des Jakarta-Projekts, und 2005 ein Hauptprojekt der Apache Software Foundation.
Heute liefert Lucene zwar den Kern einer Suche, aber isoliert eingesetzt ist noch keine umfassende Suchfunktion realisierbar. Aufbauend auf der Lucene-Technik haben sich daher Projekte wie Nutch, Compass, Hounder oder Solr entwickelt. Insbesondere Solr verdient eine weitergehende Betrachtung.
Solr – so funktional wie die Google-Suche
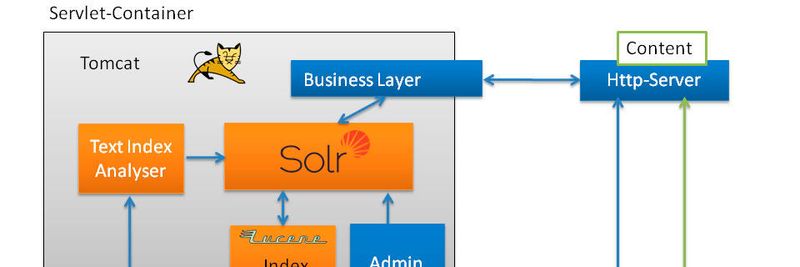
Bei Solr handelt es sich um ein in Lucene enthaltenes Servlet für Container wie Apache Tomcat oder Jetty. Ursprünglicher Entwickler von Solr war CNET, das die Technik anfangs „Solar“ (Search on Lucene and Resin) nannte. Ebenso wie Tomcat ist Resin ein Servlet Container.
Solr kommuniziert über http: mittels http Post ist es z. B. möglich, verschiedenste Dateiformate – von XML über JSON bis hin zu PDF – zu verarbeiten bzw. zu indizieren. Abfragen erfolgen mittels http Get. Daneben bietet Solr weitere Features, wie etwa Highlighting, Ähnlichkeitssuche, facettierte Suche, Expertensuche, Phrasensuche, Rechtschreibprüfung, Autosuggestion und umfassende Analytics-Funktionalitäten, wie etwa gesuchte Wörter (Phrasen), gewählte Treffer etc.
In Summe erreicht Solr den Funktionsumfang der klassischen Google-Suche und ist zudem sowohl skalierbar als auch hochperformant. Mit rund 6.000 Downloads pro Tag zählt Lucene zu den erfolgreichsten Open-Source-Projekten – entsprechend groß sind die Community und die Knowledge Base im Netz. Zudem verfügt Solr über eine sehr gute Dokumentation, sodass auch in unternehmenskritischen Szenarien ausreichend Stabilität und Zukunftssicherheit gewährleistet sind.
Architektur von Solr
Um Solr einsetzen zu können, gibt es nur eine technische Voraussetzung: die Installation eines Java Development Kit (JDK) bzw. einer Java Runtime Environment (JRE) auf einem beliebigem Betriebssystem. Als Servlet Container ist eine Tomcat- oder Jetty-Instanz nötig, die die Apache Solr Webapp ausführt.
Mit einigen Parsern ausgeliefert, kann Solr spezielle Formate wie PDF, XML oder HTML interpretieren und das Ergebnis entsprechend indizieren. Für besondere Anforderung kann es ggf. erforderlich sein, zusätzliche Parser einzusetzen. Um Verzeichnisse oder Repositories zu durchsuchen, kommen Crawler zum Einsatz, die einen Verzeichnisbaum „spidern“.
Mächtiges Gesamtsystem
Was auf dem ersten Blick recht einfach erscheint, birgt aufgrund der Mächtigkeit des Gesamtsystems eine hohe Komplexität: Lucene ist eine Java-Bibliothek mit der Komponente Solr, diversen Parsern und Crawlern sowie Request Handlern und ermöglicht unter anderem die Einbindung in eine Servlet-Umgebung, die Aufbereitung der Trefferliste, das Rendering im Browser und die Anbindung von Solr an ein Active Directory oder LDAP – samt Abgleich gegen die Zugriffsrechte.
Für einige Komponenten stehen entsprechende Webfrontends zwecks Administration bereit, andere Konfigurationen erfolgen per Konsole und Texteditor. All das macht Lucene/Solr-Projekte zu einer großen Herausforderung. Aufgrund der Komplexität ist es umso wichtiger, ein passgenaues Gesamtpaket einzusetzen – harmonisch abgestimmt, wodurch sich die Konfiguration stark vereinfacht.
Den individuellen Bedarf ermitteln
Für eine maßgeschneiderte Suchlösung sollten zu Beginn der Planung eine Analyse der relevanten Daten und eine Präzisierung der Anforderungen erfolgen: Welche Datensilos und Dateiformate, wie etwa Word-, PDF- oder PPT-Dokumente, sind zu berücksichtigen? Gehören E-Mails dazu? Welche Benutzerrechte sollen greifen? Ist Mehrsprachigkeit gefordert?
Da Solr "out of the box" entsprechende Funktionalitäten bietet, lässt sich eine darauf abgestimmte Indizierung für die Darstellung von Sprachen als "Facetten" nutzen. Auch für den Betrieb sind Konzepte zu entwickeln. Zur Verarbeitung massiver Suchanfragen bietet sich z. B. der Einsatz von Replikation an: Die Indizierung führt ein Master durch, der dann auf mehrere Slaves repliziert wird.
Sind Suchabfragen statistisch zu erfassen? Sollen die Systeme on premise betrieben werden? Das würde maximale Konformität mit Datenschutzanforderungen und Compliance-Regeln bedeuten. Oder ist ein Höchstmaß an Flexibilität gewünscht? In diesem Fall würde sich eine Cloud-basierte Lösung anbieten.
Einsatzszenarien sprechen für sich
Auch die Einführung und der Betrieb einer Enterprise-Search-Lösung sind anspruchsvoll und erfordern ein methodisches Vorgehen, wie es in Projekten üblich ist. Dabei sind strategische Ziele ebenso zu berücksichtigen wie User Experience und Ergonomie.
Da es viele Fallstricke gibt, sollten Unternehmen hierbei auf externe Beratungsdienstleister mit großer Erfahrung zurückzugreifen. So umgehen sie altbekannte Fehler und profitieren zugleich von bewährten Best-Practice-Ansätzen. Die Vorzüge und Leistungsfähigkeit von Lucene/Solr sprechen für sich.
Die folgenden Beispiele sprechen für sich. Nicht nur die Wikipedia-Suche basiert auf Apache Lucene, die Technik kommt auch bei ImmobilienScout24, Zalando, Twitter, XING, LinkedIn und SoundCloud zum Einsatz.
(ID:43770263)
:quality(80)/p7i.vogel.de/wcms/8e/22/8e228bde305b20ab98485e007aa6ee8a/0130019013v1.jpeg "Die Starburst-Datenplattform ermöglicht einen schnellen, sicheren Zugriff auf Daten unabhängig vom Speicherort. Über den AI Data Assistant sollen Anwender künftig in natürlicher Sprache auf Unternehmensdaten zugreifen können. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/13/d7/13d75e75ee19d6e744a4c082786e4918/0125791896v1.jpeg "Der Autor: Franz Kögl ist Vorstand bei Intrafind in München, einem Spezialisten für Enterprise-Search und KI. (Bild: IntraFind)")