
:quality(80)/p7i.vogel.de/wcms/85/3c/853cb31461d6645416dd13e94644f9ff/0131873297v1.jpeg "Die ETERNUS AB-Familie mit dem Fokus auf All Flash und die ETERNUS HB-Familie als hybrides Storage-System. (Bild: Fsas Technologies)")
:quality(80)/p7i.vogel.de/wcms/b5/ad/b5ade2e50671d986cabb091cc33de39f/0127234511v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/2d/69/2d69b27f3f8f5f290f7ae2b3d9123b1b/0127206601v1.jpeg "Storage-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/69/6c/696c2b13d9bd6fb14fda429dd629f8e0/0132233985v1.jpeg "Mit NovaStor DataCenter können Unternehmen und Managed-Service-Provider unterschiedliche IT-Infrastrukturen über eine zentrale Plattform absichern. (Bild: © Lemdah – stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/58/44/58441cd9d7118e15fcd55b0fdc8154ab/0132044802v1.jpeg "Datensicherheit und -resilienz sind zum IT-Dauerbrenner geworden – und wurden auf der jüngsten „A3 Technology Live“ entsprechend thematisiert. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/9e/93/9e93e7e1323e4ab084407bfb9f9b76bc/0131959646v1.jpeg "Im Gastbeitrag erläutert Christian Kubik von Commvault, wie Unternehmen sicherstellen, dass im Ernstfall eine erfolgreiche Wiederherstellung des Active Directory Forest gelingt. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/1a/21/1a2140fc83029ae7ee7f6b5069b8fb4e/0131660435v1.jpeg "Das Betriebssystem ADM basiert auf Linux und stellt verschiedene Anwendungen und Funktionen für Asustor-NAS-Geräte bereit. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ee/91/ee915ceaa48f3d7d8c2435a1791dc511/0132111353v1.jpeg "Für Everpure spielen durch die fortschreitende KI-Nutzung künftig in der IT-Landschaft von Unternehmen nicht mehr Applikationen, sondern Daten die Hauptrolle. Everpure Data Intelligence soll für die Erkennung, Klassifizierung und Kontextualisierung des gesamten Datenbestands eines Unternehmens sorgen. (Bild: © KanawatTH - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4f/e7/4fe7284b8da22c55a6f70fd0dee69258/0131888564v1.jpeg "Die Partnerschaft soll dazu dienen, parallelen Hochleistungszugriff mit automatisiertem Datenmanagement und skalierbarer Langzeitarchivierung für KI-, HPC- und Big-Data-Umgebungen zu kombinieren. (Bild: © Rawpixel.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/17/34/1734ed8bece82245fb5ba5a922690841/0132118989v1.jpeg "Zwei kritische und eine mittelschwere Sicherheitslücke in Synology MailPlus Server können zu unbefugten Dateizugriffen und DoS-Angriffen führen. (Bild: Dall-E / Vogel IT-Medien GmbH / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/7d/0c/7d0c784e6bdec5b9b4decd247403534f/0131325042v1.jpeg "Der Autor: Uwe Specht ist Prinicple Specialist Solution Consultant bei Pegasystems. (Bild: Pegasystems)")
:quality(80)/p7i.vogel.de/wcms/56/02/56020cfbb900e167982dfb9e897b9fe3/0132130673v1.jpeg "Dropbox präsentiert drei neue Integrationen für das gesamte Claude-Portfolio. (Bild: Anthropic / Dropbox)")
:quality(80)/p7i.vogel.de/wcms/4e/31/4e31cbf0807636f54ea7f6d60b7e5528/0131660732v1.jpeg "MailStore 26.2 steht ab sofort für alle Produktlinien zur Verfügung, einschließlich der Cloud-Variante und der Service Provider Edition. (Bild: MailStore)")
:quality(80)/p7i.vogel.de/wcms/99/b8/99b80de8dcbb3f9c1dc64e7e095c417c/0130967771v1.jpeg "LTFS ist ein Dateisystem für LTO-Bänder. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/28/65/2865b5fb786b06c20843680f48e24baa/0132305562v1.jpeg "Storage anders denken: Open Source Storage macht souverän, ein Interview von Oliver Schonschek, Insider Research, mit Joachim Kraftmayer von Clyso. (Bild: Vogel IT-Medien / Clyso / Schonschek)")
:quality(80)/p7i.vogel.de/wcms/6b/c3/6bc30ac79b0dc05e39a6f93b228c0e5f/0132228780v1.jpeg "„Souveränität muss ganzheitlich gedacht werden“ – Sven Selle, Senior Director Field Engineering EMEA bei Dataiku. (Bild: Vogel IT-Medien / Dataiku)")
:quality(80)/p7i.vogel.de/wcms/83/28/8328abac86a012020e43ddbf0577724b/0131659829v1.jpeg "Garage repliziert die Daten automatisch auf Server an unterschiedlichen Standorten. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/83/05/8305d761efa7abf31d460ec608c8d996/0130966888v1.jpeg "DDR-SDRAM ist der Arbeitsspeicherstandard. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/fd/6b/fd6b010488a6aaa362882a81a39b644e/0131446091v1.jpeg "LightOS von Lightbits wurde speziell für hohe Leistung, geringe Latenz und gute Skalierbarkeit entwickelt. (Bild: Gemini / KI-generiert)")
:quality(80)/images.vogel.de/vogelonline/bdb/1552300/1552323/original.jpg "Cloud-Speicher für Einsteiger – Microsoft OneDrive zusammen mit macOS und iOS nutzen. (©georgejmclittle - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1644500/1644561/original.jpg "Online-Speicher bei Web.de und GMX: So funktioniert die Verwaltung. (© stokkete - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1641800/1641842/original.jpg "All-Flash-Arrays versprechen unschlagbar niedrige Latenzen. (© pozdeevvs - stock.adobe.com)")
Berufsbild Data Scientist Fachliche Vielseitigkeit und Kreativität sind gefragt
Bei Big-Data-Projekten fällt der Rolle des Data Scientist eine Schlüsselfunktion zu: Dieser Mitarbeiter, der Kenntnisse in Mathematik, Informatik und Betriebswirtschaft vereint, kommuniziert den möglichen Mehrwert von analytischen Resultaten an die Unternehmensleitung. So wird er Teil von strategischen Entscheidungsprozessen.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
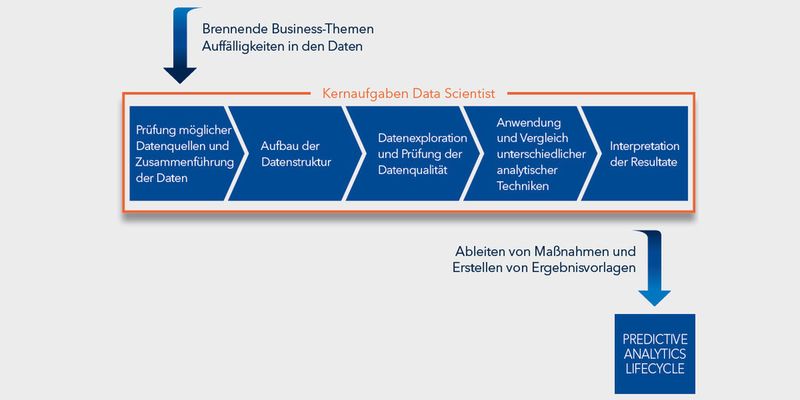
Was macht eigentlich ein Data Scientist? SAS Institute Education beschreibt in einem Whitepaper die Aufgaben so: „Data Scientists arbeiten an der Schnittstelle zwischen Daten und Business. Ihre Aufgabe ist es, geschäftsrelevante Besonderheiten oder Zusammenhänge in den Daten eines Unternehmens zu identifizieren, zu analysieren und sie als Entscheidungsgrundlage für Management oder Fachabteilungen aufzubereiten.“
Das bedeutet: „Data Scientists haben die Aufgabe, Big Data in ,Big Value‘ zu wandeln“, erläutert der Unternehmensberater Wolfgang Martin. „Sie sind verantwortlich für die Methodologie von Big-Data-Analytik sowie die Kommunikation von analytischen Resultaten gegenüber dem Vorstand und dem gesamten Unternehmen.“ Mit anderen Worten: Für die Wertschöpfung von Big Data sind Data Scientist unverzichtbar.
„Data Scientists übernehmen das Organisieren der Daten und das Bauen von analytischen Modellen im Rahmen des Projektes“, präzisiert Martin. „Dazu gehört auch das Überprüfen, Ändern und Ersetzen von Modellen, falls notwendig, sowie die Kommunikation von analytischen Resultaten.“
Idealanforderungen
Laut Martin handelt es sich um Mitarbeiter, die eher im Bereich Business Intelligence angesiedelt sind und folgende Eigenschaften idealerweise mitbringen:
- 1. Technische Expertise: Tiefe Kenntnisse in einer Natur- oder Ingenieurs-Wissenschaft sind notwendig. Sie bilden die Grundlage, um als Data Scientist erfolgreich arbeiten zu können. Insofern sollte man zukünftige Data Scientists in dieser Gruppe suchen und dann auch die weiteren geforderten Eigenschaften testen.
- 2. Problembewusstsein: Die Fähigkeit, ein Problem in überprüfbare Hypothesen aufzubrechen.
- 3. Kommunikation: Die Fähigkeit, komplexe Dinge per Anekdoten durch einfach verständliche und gut kommunizierbare Sachverhalte darzustellen.
- 4. Kreativität: Die Fähigkeit, Probleme mit anderen Augen zu sehen und anzugehen („thinking out of the box“).
SAS ist nicht so streng bei der Stellenbeschreibung: „In jedem Unternehmen gibt es Mitarbeiter, die die Voraussetzungen mitbringen, sich zum Data Scientist weiterzubilden. Dafür sind Talent und Veranlagung, Flexibilität und Lust auf Neues erforderlich. Und eine Grundausstattung an technisch-methodischem Know-how.“
Unterschiedliche Karrierewege
Der Weg zum Data Scientist kann demnach ganz unterschiedlich verlaufen und hängt sowohl vom Unternehmen als auch vom jeweiligen Mitarbeiter ab: Manche kommen aus dem technisch-naturwissenschaftlichen Bereich und haben sich das notwendige Business Know-how angeeignet. Andere starten mit Fachabteilungsperspektive, beispielsweise aus Marketing, Vertrieb oder Controlling, und bilden sich in den erforderlichen technischen Disziplinen weiter.
Stephan Reimann und Alexander Richthammer sind IBM-Mitarbeiter aus der Praxis der Big-Data-Analyse. „Der Data Scientist“, so Reimann, „kümmert sich mithilfe von Data Mining um die Frage, wie sein Unternehmen bzw. seine Organisation Wissen und Nutzen aus Daten ziehen kann. Im Rahmen von Data Mining setzt er auch ETL-Tools ein. Seine Arbeitsweise ist vor allem explorativ.“ Daher benötige der Data Scientist als berufliche Vorbildung Mathematik, BWL und/oder Informatik. „Fachliche Geschäftsprozesse zu kennen, ist etwa für Disziplinen wie Predictive Maintenance wichtig“, weiß Reimann.
Kein Allround-Talent
Aber der Data Scientist braucht kein Allround-Talent zu sein. Um möglichst effektiv arbeiten zu können, ist er Teil eines Dream Teams, dessen Rollen – nicht Stelle – McKinsey für Big Data skizziert hat:
- 1. Data Hygienists stellen sicher, dass die Daten bereinigt und richtig sind und auch über den Lebenszyklus der Daten so bleiben. Dieses Data Profiling und Cleansing beginnt ganz am Anfang des Projektes, wenn die ersten Daten erfasst werden. Daran sind alle Team-Mitglieder beteiligt, die diese Daten nutzen wollen. Eine bekanntere Stellenbezeichnung dafür ist Data Steward.
- 2. Data Explorers durchsuchen das Big-Data-Universum, um die Daten aufzufinden, die man im Projekt braucht. Dazu gehört auch die Aufbereitung der Daten für das Projekt, denn die meisten Daten draußen wurden nicht erzeugt, um analytisch untersucht zu werden, sind also weder für eine Analyse geeignet noch angemessen gespeichert oder organisiert.
- 3. Business Solution Architects haben die Aufgabe, die identifizierten Daten zusammenzustellen und für die Analyse vorzubereiten. Dazu werden die Daten auch für die erwarteten Abfragen strukturiert. Daten, die im Minuten- oder Stundentakt benötigt werden, müssen dann auch entsprechend aufgefrischt werden.
- 4. Data Scientists übernehmen das Organisieren der Daten und das Bauen von analytischen Modellen im Rahmen des Projektes. Dazu gehört auch das Überprüfen, Ändern und Ersetzen von Modellen, wenn notwendig, sowie die Kommunikation von analytischen Resultaten gegenüber dem Vorstand und dem gesamten Unternehmen.
- 5. Campaign Experts haben die Aufgaben, die Ergebnisse zu interpretieren und in entsprechende Aktionen umzusetzen in. Dazu gehören auch das Priorisieren von Kanälen und das Festlegen der Kampagnen-Sequenzen.
„Die Rollen der Data Explorers und Campaign Experts benötigen Expertisen wie Cognitive Scientists und Behavioral Economists“, erläutert Wolfgang Martin. „Solche Expertise ist notwendig, um zu identifizieren, welche Daten für das Projekt wichtig sind und welche nicht. Sie ist auch von großer Hilfe in der Interpretation von Ergebnissen und entsprechenden Umsetzungen.“ Im Hinblick auf Information Governance ist der Data Steward die ideale Ergänzung zum Data Scientist: „Er spielt in der Big-Data-Analytik die Rolle eines SWAT-Teams, also eines taktisch agierenden Spezialteams, und nicht die strategische Rolle wie im Unternehmen.“
Der Data Scientist in der Praxis
Soweit die Theorie. Die reale Arbeitsweise des Data Scientist sieht ebenfalls sehr spannend aus. „Dazu gehört die Aufbereitung von Datenquellen und die Bildung von Datenkategorien“, erzählen Stephan Reimann und Alexander Richthammer von IBM. „Bei der Auswahl der passenden Technologie oder des Betriebsmodells – online oder on-premise – ist entscheidend, wie der Use Case aussieht.“ Hier ist also fachliches Wissen gefragt. „Die Cloud wird aus Kostengründen manchmal bevorzugt und sowohl Hadoop als auch NoSQL-Datenbanken, die man aus der Cloud beziehen kann, helfen, umfangreiche Datenbestände schnell und ohne Schema-Vorgabe zu durchforsten“ – ganz im Sinne der Data Exploration.
Um die Produktivität des Data Scientist zu erhöhen, insbesondere bei der Programmierung, ist eine Software gefragt, die zeitraubende Routine-Aufgaben automatisiert oder sie zumindest vereinfacht. Ein Beispiel ist IBM BigSheets, das zum Lieferumfang von InfoSphere BigInsights 3.0 gehört: „Der Vorteil von BigSheets: Der Data Scientist muss keine MapReduce-Jobs mehr in Java schreiben usw., sondern erledigt seine Aufgabe anhand von Tabellen, die zusammengeführt und gemappt werden“, berichtet Reimann. Daher der Name „sheets“ – Tabellen.
Viele Analyseverfahren
SPSS Modeler wird von IBM für Data Mining angeboten. Der Data Scientist bereitet mit dem Modeler Daten auf und nutzt eine Vielzahl von Data-Mining-Verfahren für die Analyse. Die Algorithmen können mit den vorgegebenen und auf Best Practices beruhenden Voreinstellungen ausgeführt werden oder bei Bedarf individuell mit sogenannten „Experteneinstellungen“ optimiert werden.
Bei Bedarf schlägt der Modeler die passenden Methoden bzw. Algorithmen zu ihrer Auswertung vor. Hierbei werden automatisiert alle relevanten Algorithmen ausgeführt und die besten Vorhersagemodelle ausgegeben. Ein von Reimann angeführtes Beispiel wären automatische Klassifizierer, die Daten kategorisieren. Modellierprozesse lassen sich als sogenannte „Streams“ in der Process Modeling Markup Language (PMML) ablegen und wiederverwenden. „Auf die Modellierung entfallen zehn bis 30 Prozent der Arbeit“, berichtet der Data Scientist.
Auch die Leistungssteigerung fällt ins Aufgabengebiet von Data Scientist und SPSS Modeler. „Die Methode des SQL Pushback verhindert, dass große Datenmengen – Big Data – übers Netz geschickt werden“, so Richthammer. Somit wird das Netzwerk entlastet. „Dazu werden Anweisungen und Regeln des Modelers an die Datenbank oder Hadoop geschickt und dort ausgeführt. Nur das Ergebnis wird übers Netzwerk zurückgeschickt.“ Bei Messungen lieferte der Einsatz von SQL Pushback erhebliche Performance-Gewinne und die Produktivität des Data Scientist wurde verbessert.
Anwendungsbeispiele und Erfolge
Mit seiner Arbeit kann der Data Scientist beispielsweise Kündigungen, etwa bei Personal, Versicherung, Mobilfunkverträgen usw., vorhersagen. „Im E-Commerce ist die Vorhersage des Kundenverhaltens von großer Bedeutung“, weiß Richthammer. Denn nur ein so optimierter Webshop ist ein profitabler Webshop.
SAS Education, IBM und EMC gehören zu den Unternehmen, die attraktive und detailliert beschriebene Ausbildungskurse zum Data Scientist anbieten. Pedro DeSouza, ein leitender Data Scientist bei EMC, freut sich: "Einer meiner Kunden konnte durch Analysen Kosten im zweistelligen Millionenbereich einsparen. Bei diesem Projekt haben wir fünf Millionen Caller Detail Records (CDR) untersucht. Durch die entsprechenden Analysen konnten wir ermitteln, bei welchen Nutzern Serviceprobleme auftraten. Bis dahin wurden bei Tausenden Kunden überflüssige, aber kostspielige Reparaturen ausgeführt.“
Durch eine weitere Datenmodellierung, den „Churn-Algorithmus“, konnte auch die Abwanderung („churn“) von Handykunden um 30 Prozent gesenkt werden. Dass Big Data nicht immer teuer sein muss, zeigt DeSouzas drittes Beispiel: „Ich konnte dazu beitragen, dass die Kosten für Big-Data-Analysen in einem Unternehmen von rund zehn Millionen US-Dollar auf 100.000 US-Dollar pro Jahr gesenkt wurden. Für die entsprechende kleine Änderung musste nicht einmal der laufende Betrieb unterbrochen werden.“
(ID:43210864)
:quality(80)/p7i.vogel.de/wcms/2f/d2/2fd28f95928f3cd2a38f75b29ed742d8/0126827011v1.jpeg "Damit der Data Lake nicht „versumpft“, braucht es ein durchdachtes Governance-Konzept. (Bild: © vladimircaribb - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/04/9b/049b7956de156bc143c00c9913296854/0128008177v1.jpeg "Um KI- und Machine-Learning-Modelle zu trainieren, werden enorme Mengen an Daten benötigt. (Bild: Midjourney / KI-generiert)")