
:quality(80)/p7i.vogel.de/wcms/85/3c/853cb31461d6645416dd13e94644f9ff/0131873297v1.jpeg "Die ETERNUS AB-Familie mit dem Fokus auf All Flash und die ETERNUS HB-Familie als hybrides Storage-System. (Bild: Fsas Technologies)")
:quality(80)/p7i.vogel.de/wcms/b5/ad/b5ade2e50671d986cabb091cc33de39f/0127234511v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/2d/69/2d69b27f3f8f5f290f7ae2b3d9123b1b/0127206601v1.jpeg "Storage-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/9e/93/9e93e7e1323e4ab084407bfb9f9b76bc/0131959646v1.jpeg "Im Gastbeitrag erläutert Christian Kubik von Commvault, wie Unternehmen sicherstellen, dass im Ernstfall eine erfolgreiche Wiederherstellung des Active Directory Forest gelingt. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c4/25/c42592748ab836d82ba68d0f9569fbc7/0131394188v1.jpeg "Ari Albertini, CEO von FTAPI, weist darauf hin, dass moderne Cyberangriffe oft gezielt auf die Kommunikationsfähigkeit von Unternehmen zielten. Wer Krisenkommunikation erst im Ernstfall improvisiere, habe bereits verloren. Resilienz entstehe vor der Krise, nicht währenddessen. (Bild: Ftapi)")
:quality(80)/p7i.vogel.de/wcms/4c/8d/4c8d6027854b54223233416abd4a1072/0132101289v1.jpeg "Mit der richtigen Resilienz-Strategie gegen destruktive Schadsoftware. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/2e/682e8e39bcd5d3d9d4027371a054753a/0132027249v1.jpeg "PCIe-SSD-Plattform A2000: zum Marktstart verfügbar im M.2-2280-Formfaktor mit Kapazitäten bis zu 4 TB. (Bild: Swissbit)")
:quality(80)/p7i.vogel.de/wcms/83/05/8305d761efa7abf31d460ec608c8d996/0130966888v1.jpeg "DDR-SDRAM ist der Arbeitsspeicherstandard. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dc/36/dc36b60072445217768d71dec968bd9f/0131373651v1.jpeg "Mit Hard Disk Validator lässt sich der physische Zustand von HDDs und SSDs bewerten – ohne den Datenträger öffnen zu müssen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/a9/a8/a9a86f9bb9ef143c79bcb4f3eab436fe/0131380440v1.jpeg "Die In-Memory-Geodatenbank Tile38 eignet sich speziell für Anwendungen mit einer hohen Aktualisierungsrate von Standortdaten. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/56/02/56020cfbb900e167982dfb9e897b9fe3/0132130673v1.jpeg "Dropbox präsentiert drei neue Integrationen für das gesamte Claude-Portfolio. (Bild: Anthropic / Dropbox)")
:quality(80)/p7i.vogel.de/wcms/cd/82/cd82273cb5ceace0da8c674960790001/0131693028v2.jpeg "Data Lineage macht sichtbar, wohin Daten wirklich fließen. Mit dem Vormarsch autonomer KI-Agenten wird Nachverfolgbarkeit zur operativen Notwendigkeit für Sicherheitsteams. (Bild: © Natalia - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/7d/0c/7d0c784e6bdec5b9b4decd247403534f/0131325042v1.jpeg "Der Autor: Uwe Specht ist Prinicple Specialist Solution Consultant bei Pegasystems. (Bild: Pegasystems)")
:quality(80)/p7i.vogel.de/wcms/1d/e0/1de08813440de6d240cac3d9a1530839/0132027218v1.jpeg "Commvault: Definition von Sicherungsgruppen in Microsoft Azure. (Bild: Commvault)")
:quality(80)/p7i.vogel.de/wcms/b5/93/b593e2dc758999b312a67e7bf61915a4/0131265436v1.jpeg "Europa verfügt sowohl über das nötige technische Know-how als auch die erforderlichen regulatorischen Rahmenbedingungen, um ein KI-Modell zu etablieren, das leistungsstark, überprüfbar und frei von aufgezwungenen Abhängigkeiten ist. (Bild: © ImageFlow - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4e/31/4e31cbf0807636f54ea7f6d60b7e5528/0131660732v1.jpeg "MailStore 26.2 steht ab sofort für alle Produktlinien zur Verfügung, einschließlich der Cloud-Variante und der Service Provider Edition. (Bild: MailStore)")
:quality(80)/p7i.vogel.de/wcms/99/b8/99b80de8dcbb3f9c1dc64e7e095c417c/0130967771v1.jpeg "LTFS ist ein Dateisystem für LTO-Bänder. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/04/cc/04ccc504aee183fd610969ddf31ebbc1/0130625872v1.jpeg "Für praktisch jeden Speicherzweck findet der geneigte Kunde auch passende europäische Angebote. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/83/28/8328abac86a012020e43ddbf0577724b/0131659829v1.jpeg "Garage repliziert die Daten automatisch auf Server an unterschiedlichen Standorten. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/7f/2a/7f2a7e8f87b8c6f7e90b7ff2a7e0d441/0132130047v1.jpeg "Sandeep Singh von NetApp: „StorageGRID 12.1 bietet Kunden einen global einheitlichen Namespace, um Daten im großen Maßstab zu verwalten und KI- und Analytics-Workloads zu beschleunigen.“ (Bild: NetApp)")
:quality(80)/p7i.vogel.de/wcms/67/b9/67b9217728360a62f389fb352e913ba5/0132130022v1.jpeg "Pyramid und Scality gehen eine strategische Partnerschaft für Hochleistungs-KI- und Objektspeicherlösungen ein. (Bild: © ImageFlow – stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/fd/6b/fd6b010488a6aaa362882a81a39b644e/0131446091v1.jpeg "LightOS von Lightbits wurde speziell für hohe Leistung, geringe Latenz und gute Skalierbarkeit entwickelt. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/59/4e/594e382999d9a47b5403169895e3ec2a/0131438659v1.jpeg "Simplyblock stellt NVMe-basierten, softwaredefinierten Block-Storage für I/O-intensive Workloads auf Kubernetes, Red Hat OpenShift und virtuellen Maschinen bereit. (Bild: Gemini / KI-generiert)")
:quality(80)/images.vogel.de/vogelonline/bdb/1552300/1552323/original.jpg "Cloud-Speicher für Einsteiger – Microsoft OneDrive zusammen mit macOS und iOS nutzen. (©georgejmclittle - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1644500/1644561/original.jpg "Online-Speicher bei Web.de und GMX: So funktioniert die Verwaltung. (© stokkete - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1641800/1641842/original.jpg "All-Flash-Arrays versprechen unschlagbar niedrige Latenzen. (© pozdeevvs - stock.adobe.com)")
Baumstrukturen und Triples helfen bei der schnellen Datenrecherche Marklogic NoSQL trianguliert semi-unstrukturierte Datenbanken
Das stete Wachstum unstrukturierter Daten begeistert verständlicherweise die Speicherbranche. So lassen sich selbst bei sinkenden Produktpreisen Umsatzsteigerungen erzielen. Was man dann mit dem gespeicherten Datenmassenmonster anfängt, darüber dürfen sich andere den Kopf zerbrechen.
Anbieter zum Thema
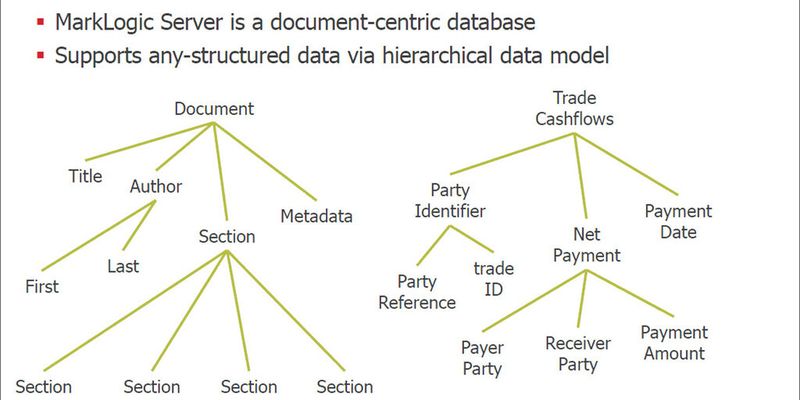
Unstrukturierte Daten durchsucht man per NoSQL-Datenbanken wie denen von MongoDB, CouchDB Redis, Riak, Neo4J, InfoGrid oder Infinite Graph. Die Suche kann auf Hashwerten basieren, was aber das Ersetzen von Inhalten schwer macht und auch bei Abfragen schwerfällig ist. Die bessere Alternative ist eine spaltenorientierte NoSQL-Datenbank, wie sie Facebook mit Cassandra und Hbase bei riesigen Datenmengen einsetzt.
Eine dritte Variante führt die Suche auf dem höherwertigen Level von Dokumenten durch, wie es vor vielen Jahren Lotus mit Notes etablierte und schon damals dafür viel Lob erntete. Hashwerte und teilstrukturierte Dokumente, bzw. Versionen davon, werden heute allerdings in einem kompakten Datenformat auf Basis von JSON-Strukturen (Javascript Object Notation) gespeichert.
Dokumentenzentrisches Modell
Eine vierte Möglichkeit, die sich für den kommerziellen Einsatz eignet, sind Datenbanken mit Baumstrukturen, die sich gut parallelisieren lassen, denen derzeit jedoch noch eine Art allseits akzeptierte Abfragesprache wie SQL fehlt. Das amerikanische Unternehmen Marklogic, ein Verfechter des dokumentenzentrierten Modells, verwendet zum Beispiel die vom W3c empfohlene rekursive Abfragesprache Sparql.
Gegründet wurde Marklogic 2001 im Silicon Valley. Es gibt Büros in New York, London, Frankfurt, Utrecht und Tokyo. Die Startup-Phase ist inzwischen beendet und das Unternehmen hat das wohl aufregendste Großereignis auf diesem Globus schon hinter sich. Nur zehn Jahre nach seiner Gründung hat Marklogic gemeinsam mit der BBC einen der schwersten öffentlichen Jobs gemeistert: Die publizistische Aufbereitung der Olympischen Sommerspiele 2012 in London.
RDF ganz einfach: Subjekt, Prädikat und Objekt
Mit diesem Nachweis, dass man ein dynamisches Content-Publishing für zig Millionen Sportbegeisterte in Echtzeit bereitstellen kann, wurde auch der Beweis erbracht, dass das Marklogic-NoSQL-Datenbankprodukt Enterprise-tauglich ist.
Die dazu erforderliche Technik beschreibt Gary Bloom, CEO bei Marklogic, so: „Es gibt zwei wichtige Schlüsselfunktionen, den Triple-Store und den NoSQL-Inhaltespeicher. Der Triple Store ist wichtig, um automatisch Inhalte zusammenzufassen, zu publizieren und auch wieder in andere Zusammenhänge zu bringen.“
(ID:42666109)
:quality(80)/p7i.vogel.de/wcms/25/84/2584b7e9528508550d1ffce8185d3173/0125601832v1.jpeg "Auf Grund der zunehmenden Komplexität der Infrastrukturen steigen auch die Anforderungen ans Datenbank-Management. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/2b/eb/2beb093a4b15a43e77a5fddc51617012/0129334977v1.jpeg "Der Remote Dictionary Server ist ein quelloffener Datenspeicher mit einer einfachen Schlüssel-Werte-Datenstruktur und legt die Daten direkt im Arbeitsspeicher ab. (Bild: Midjourney / KI-generiert)")