
:quality(80)/p7i.vogel.de/wcms/85/3c/853cb31461d6645416dd13e94644f9ff/0131873297v1.jpeg "Die ETERNUS AB-Familie mit dem Fokus auf All Flash und die ETERNUS HB-Familie als hybrides Storage-System. (Bild: Fsas Technologies)")
:quality(80)/p7i.vogel.de/wcms/b5/ad/b5ade2e50671d986cabb091cc33de39f/0127234511v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/2d/69/2d69b27f3f8f5f290f7ae2b3d9123b1b/0127206601v1.jpeg "Storage-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/9e/93/9e93e7e1323e4ab084407bfb9f9b76bc/0131959646v1.jpeg "Im Gastbeitrag erläutert Christian Kubik von Commvault, wie Unternehmen sicherstellen, dass im Ernstfall eine erfolgreiche Wiederherstellung des Active Directory Forest gelingt. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c4/25/c42592748ab836d82ba68d0f9569fbc7/0131394188v1.jpeg "Ari Albertini, CEO von FTAPI, weist darauf hin, dass moderne Cyberangriffe oft gezielt auf die Kommunikationsfähigkeit von Unternehmen zielten. Wer Krisenkommunikation erst im Ernstfall improvisiere, habe bereits verloren. Resilienz entstehe vor der Krise, nicht währenddessen. (Bild: Ftapi)")
:quality(80)/p7i.vogel.de/wcms/4c/8d/4c8d6027854b54223233416abd4a1072/0132101289v1.jpeg "Mit der richtigen Resilienz-Strategie gegen destruktive Schadsoftware. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/2e/682e8e39bcd5d3d9d4027371a054753a/0132027249v1.jpeg "PCIe-SSD-Plattform A2000: zum Marktstart verfügbar im M.2-2280-Formfaktor mit Kapazitäten bis zu 4 TB. (Bild: Swissbit)")
:quality(80)/p7i.vogel.de/wcms/83/05/8305d761efa7abf31d460ec608c8d996/0130966888v1.jpeg "DDR-SDRAM ist der Arbeitsspeicherstandard. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dc/36/dc36b60072445217768d71dec968bd9f/0131373651v1.jpeg "Mit Hard Disk Validator lässt sich der physische Zustand von HDDs und SSDs bewerten – ohne den Datenträger öffnen zu müssen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/a9/a8/a9a86f9bb9ef143c79bcb4f3eab436fe/0131380440v1.jpeg "Die In-Memory-Geodatenbank Tile38 eignet sich speziell für Anwendungen mit einer hohen Aktualisierungsrate von Standortdaten. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/56/02/56020cfbb900e167982dfb9e897b9fe3/0132130673v1.jpeg "Dropbox präsentiert drei neue Integrationen für das gesamte Claude-Portfolio. (Bild: Anthropic / Dropbox)")
:quality(80)/p7i.vogel.de/wcms/cd/82/cd82273cb5ceace0da8c674960790001/0131693028v2.jpeg "Data Lineage macht sichtbar, wohin Daten wirklich fließen. Mit dem Vormarsch autonomer KI-Agenten wird Nachverfolgbarkeit zur operativen Notwendigkeit für Sicherheitsteams. (Bild: © Natalia - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/7d/0c/7d0c784e6bdec5b9b4decd247403534f/0131325042v1.jpeg "Der Autor: Uwe Specht ist Prinicple Specialist Solution Consultant bei Pegasystems. (Bild: Pegasystems)")
:quality(80)/p7i.vogel.de/wcms/1d/e0/1de08813440de6d240cac3d9a1530839/0132027218v1.jpeg "Commvault: Definition von Sicherungsgruppen in Microsoft Azure. (Bild: Commvault)")
:quality(80)/p7i.vogel.de/wcms/b5/93/b593e2dc758999b312a67e7bf61915a4/0131265436v1.jpeg "Europa verfügt sowohl über das nötige technische Know-how als auch die erforderlichen regulatorischen Rahmenbedingungen, um ein KI-Modell zu etablieren, das leistungsstark, überprüfbar und frei von aufgezwungenen Abhängigkeiten ist. (Bild: © ImageFlow - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4e/31/4e31cbf0807636f54ea7f6d60b7e5528/0131660732v1.jpeg "MailStore 26.2 steht ab sofort für alle Produktlinien zur Verfügung, einschließlich der Cloud-Variante und der Service Provider Edition. (Bild: MailStore)")
:quality(80)/p7i.vogel.de/wcms/99/b8/99b80de8dcbb3f9c1dc64e7e095c417c/0130967771v1.jpeg "LTFS ist ein Dateisystem für LTO-Bänder. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/04/cc/04ccc504aee183fd610969ddf31ebbc1/0130625872v1.jpeg "Für praktisch jeden Speicherzweck findet der geneigte Kunde auch passende europäische Angebote. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/83/28/8328abac86a012020e43ddbf0577724b/0131659829v1.jpeg "Garage repliziert die Daten automatisch auf Server an unterschiedlichen Standorten. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/7f/2a/7f2a7e8f87b8c6f7e90b7ff2a7e0d441/0132130047v1.jpeg "Sandeep Singh von NetApp: „StorageGRID 12.1 bietet Kunden einen global einheitlichen Namespace, um Daten im großen Maßstab zu verwalten und KI- und Analytics-Workloads zu beschleunigen.“ (Bild: NetApp)")
:quality(80)/p7i.vogel.de/wcms/67/b9/67b9217728360a62f389fb352e913ba5/0132130022v1.jpeg "Pyramid und Scality gehen eine strategische Partnerschaft für Hochleistungs-KI- und Objektspeicherlösungen ein. (Bild: © ImageFlow – stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/fd/6b/fd6b010488a6aaa362882a81a39b644e/0131446091v1.jpeg "LightOS von Lightbits wurde speziell für hohe Leistung, geringe Latenz und gute Skalierbarkeit entwickelt. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/59/4e/594e382999d9a47b5403169895e3ec2a/0131438659v1.jpeg "Simplyblock stellt NVMe-basierten, softwaredefinierten Block-Storage für I/O-intensive Workloads auf Kubernetes, Red Hat OpenShift und virtuellen Maschinen bereit. (Bild: Gemini / KI-generiert)")
:quality(80)/images.vogel.de/vogelonline/bdb/1552300/1552323/original.jpg "Cloud-Speicher für Einsteiger – Microsoft OneDrive zusammen mit macOS und iOS nutzen. (©georgejmclittle - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1644500/1644561/original.jpg "Online-Speicher bei Web.de und GMX: So funktioniert die Verwaltung. (© stokkete - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1641800/1641842/original.jpg "All-Flash-Arrays versprechen unschlagbar niedrige Latenzen. (© pozdeevvs - stock.adobe.com)")
Analysedaten für BI speichern und lesen Apache Druid – Datenspeicher mit geringen Latenzen
Apache Druid ist ein Open-Source-Analysespeicher, der Business-Intelligence-Abfragen von Ereignisdaten mit geringer Latenz ermöglicht. Echtzeitzugriffe sind genauso möglich wie eine schnelle Datenaggregation.
Anbieter zum Thema
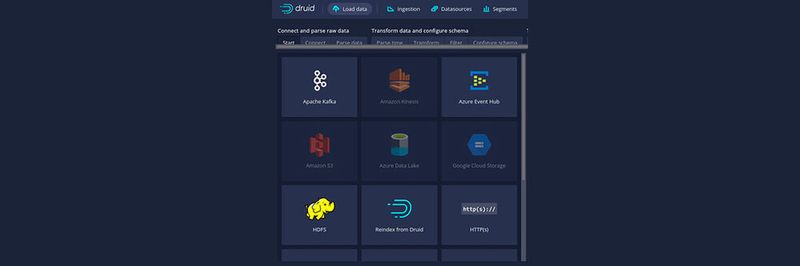
Apache Druid ist als Echtzeit-Analyse-Datenbank für große Datenmengen bekannt geworden. Der Fokus von Apache Druid liegt in der Leistung. Analysedaten sollen in Echtzeit verarbeitet werden können. Sinnvoll ist das zum Beispiel, wenn Schaubilder zur Verfügung gestellt werden sollen, bei denen Produktions- und andere Daten in Echtzeit angezeigt werden. Die Schaubilder reagieren sehr schnell, da Druid im Hintergrund die notwendigen Daten in kürzester Zeit abrufen kann. Ad-hoc-Abfragen sind mit Druid sehr performant möglich.
Apache Druid und Business Intelligence mit Data Warehouses
Apache Druid kann daher durchaus als Alternative zu herkömmlichen Data Warehouses genutzt werden. Druid hat seinen Schwerpunkt im Bereich von Ereignisdaten und Zeitreihen, kann aber auch andere Daten analysieren. Wo immer eine hohe Leistung bei der Analyse notwendig ist, kann der Betrieb von Druid sinnvoll sein.
In vielen Umgebungen wird Druid auch parallel zu Data Warehouses eingesetzt. Wo immer Echtzeit-Analyse, interaktive Oberflächen mit aktualisierenden Daten oder hochmoderne Abfrage-Apps im Einsatz sind, kann es sinnvoll sein, diese Daten aus Apache Druid zu beziehen. In einem solchen Szenario kann Druid wiederum seine Daten aus dem Data Warehouse erhalten, aufbereiten und zur Verfügung stellen. Das Data Warehouse kann parallel Berichte und Archivdaten zur Verfügung stellen.
Daten aus S3, Azure Data Lake und anderen Quellen integrieren
Die Datenbank konvertiert eingehende Daten in ein indiziertes Spaltenformat, das für OLAP-Anfragen optimiert ist. Die Datenbank unterstützt allerdings keinen In-Memory-Betrieb. Der Quellcode steht auf Github zur Verfügung. Druid unterstützt zahlreiche Datenquellen, auch in der Cloud. Beispiele dafür sind Amazon S3, Apache Kafka, Azure Event Hub, Amazon Kinesis, Google Cloud Storage, Azure Data Lake, lokale Daten und natürlich auch Daten aus Datenbanken sowie lokal gespeicherte Daten. Nach der Anbindung der Quelle liest Apache Druid diese ein und indexiert die Daten. Auch Hadoop wird von Druid unterstützt.

Wenn Echtzeit- und Streamingdaten an Druid angebunden werden, zum Beispiel über Apache Kafka, Kinesis oder Tranquility, analysiert Druid diese Daten auf Anforderung auch gleich in Echtzeit. Die Anzeige der Daten kann ebenfalls in Echtzeit erfolgen. Apache Druid kann mit Apache Hive und Apache Ambari integriert werden. Auch die Erstellung von OLAP-Cubes mit SQL oder das Abrufen bereits vorhandener Druid-Cubes ist im Rahmen der Echtzeitanalyse möglich. Weiterhin ist Replikation mit der Datenbank möglich, zum Beispiel über HDFS, S3 oder mit anderen Storage-Engines.

Einstieg in Druid
Grundsätzlich kann Apache Druid auch als Zeitreihendatenbank genutzt werden. Die mit Java entwickelte Datenbank kann lokal und in der Cloud zum Einsatz kommen. Installierbar ist Apache Druid in Linux/Unix und macOS. Da auch Docker-Container zur Verfügung stehen, ist es zudem möglich, Druid als Container zu betreiben. Zusammen mit dem Windows-Subsystem für Linux ist ein Betrieb von Druid als Container in Windows Server 2019/2022 und Windows 10 möglich.
Abfragen sind auch mit SQL möglich. Druid SQL nutzt einen SQL-Layer auf Basis von Apache Calcite. Der Parser und Planer von Apache Calcite wandelt die SQL-Abfragen in die Druid-native Form um. Abfrage sind dadurch sehr einfach möglich, genauso wie Abfragen für herkömmliche Abfragen, zum Beispiel von Microsoft SQL Server. Das bedeutet, dass SELECTs auch FROM, WHERE, GROUP BY, HAVING, ORDER BY, LIMIT, UNION ALL, EXPLAIN PLAN und Subqueries unterstützen.
Für einen Zugriff auf die Datenbank steht JDBC, aber auch RESTful HTTP/JSON-API bereit. Die Datenbank unterstützt verschiedene Programmiersprachen. Dazu gehören Clojure, JavaScript, PHP, Python, R, Ruby und Scala. Für Zugriffskontrolle können Berechtigungen auf Basis von LDAP eingerichtet werden.
Apache Druid testen: Installieren und starten
Apache Druid ist für den Betrieb in einem Cluster optimiert. Es ist für den Einstieg aber kein Problem, auch einen einzelnen Host für die Analyse zu verwenden. Eine anschließende Skalierung stellt kein Problem dar. Für erste Tests gehören auch Testdaten zum Lieferumfang, die indexiert und analysiert werden können.
Für die Installation auf Linux stehen die Installationsdateien bei Apache zur Verfügung (zur Installation wird Apache benötigt). Nach dem Download wird in das Verzeichnis der Installation gewechselt und der Quickstart-Assistent durchgeführt:
tar -xzf apache-druid-0.21.0-bin.tar.gzcd apache-druid-0.21.0./bin/start-micro-quickstartDa Apache Druid auf Java aufbaut, muss Java auf dem Rechner verfügbar sein. Ob Java richtig konfiguriert ist, kann mit dem folgenden Befehl überprüft werden:
./bin/verify-javaDie installierte Java-Version zeigt Linux mit „java -version“ an. Apache Druid nutzt Java 8. Ist auf dem System eine neuere Version installiert, ist eine Systemvariable notwendig, die mit dem folgenden Befehl gesetzt wird:
Export DRUID_SKIP_JAVA_CHECK=1Nach der Installation und dem Start steht die webbasierte Verwaltungskonsole zur Verfügung. Im Browser wird dazu die Adresse http://localhost:8888 eingegeben. Danach steht Druid zur Verfügung. Über den Assistenten ist es möglich, Datenquellen anzubinden, die Daten zu indexieren und für Abfragen zur Verfügung zu stellen.
Fazit
Wer im Unternehmen eine Datenbank braucht, die Daten in sehr schneller Zeit verarbeiten und analysieren soll, kann sich Apache Druid anschauen. Die Datenbank ist problemlos parallel zu bestehenden Analysesystemen und Data Warehouses einsetzbar. In diesem Fall kann das Einsatzgebiet darin bestehen, Ereignis- und Streamingdaten in Echtzeit zu analysieren. Die Datenbank ist schnell einsatzbereit und leicht skalierbar.
(ID:47493817)
:quality(80)/p7i.vogel.de/wcms/c8/49/c849e178b4f36c6f22115a343023fc2b/0127726759v1.jpeg "Die verteilte NoSQL-Datenbank Riak KV baut auf einer masterlosen Architektur auf. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/8e/22/8e228bde305b20ab98485e007aa6ee8a/0130019013v1.jpeg "Die Starburst-Datenplattform ermöglicht einen schnellen, sicheren Zugriff auf Daten unabhängig vom Speicherort. Über den AI Data Assistant sollen Anwender künftig in natürlicher Sprache auf Unternehmensdaten zugreifen können. (Bild: Midjourney / KI-generiert)")