
:quality(80)/p7i.vogel.de/wcms/85/3c/853cb31461d6645416dd13e94644f9ff/0131873297v1.jpeg "Die ETERNUS AB-Familie mit dem Fokus auf All Flash und die ETERNUS HB-Familie als hybrides Storage-System. (Bild: Fsas Technologies)")
:quality(80)/p7i.vogel.de/wcms/b5/ad/b5ade2e50671d986cabb091cc33de39f/0127234511v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/2d/69/2d69b27f3f8f5f290f7ae2b3d9123b1b/0127206601v1.jpeg "Storage-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/93/3b/933bdfb2e46fb84889ba076cdb96528c/0132367313v1.jpeg "Die Souveränitätslücke: 91 Prozent würden deutsche Cloud-Anbieter bevorzugen; tatsächlich genutzt werden sie von 53 Prozent. (Bild: Bitkom Research)")
:quality(80)/p7i.vogel.de/wcms/05/54/0554ac8c5aaed71dfb6b183a3385b479/0131805680v1.jpeg "Libre Workspace richtet sich an Einzelpersonen, Familien und den Mittelstand. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ef/9a/ef9a3c7b3700995c177a5015bce7d8f9/0131969938v1.jpeg "Mit jeder neuen SaaS-Anwendung wächst die Sicherheitslücke: Blinde Flecken führen aber zu Defiziten bei der Datensicherung und bringen mittelständische Unternehmen in größte Gefahr. (Bild: © Rawf8 - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/2f/34/2f348ad7f5f5627c93eea7c7068ef8e1/0131666436v1.jpeg "Mit Unraid lassen sich Network Attached Storage (NAS), Anwendungsserver und Virtualisierungshosts umsetzen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c4/ad/c4ad8aef9dff03452c5f16f62c253a5d/0132431753v1.jpeg "NetApp-CEO George Kurian begründet die Übernahme mit wachsenden Anforderungen an die Dateninfrastruktur im Zuge leistungsfähigerer KI-Modelle und Chips. (Bild: NetApp)")
:quality(80)/p7i.vogel.de/wcms/da/5f/da5f00440edb417c5d96f96fc6eaae65/0132112341v1.jpeg "Die Verbindlichkeit beim Beschaffungsprozess hat sich verändert. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/4b/dc/4bdce5cad97345c3eb014b9e659ac3e4/0131984341v1.jpeg "Mit FileBrowser erhalten Admins einen schlanken Dateimanager für einzelne Verzeichnisse mit getrennter Ablage von Konfiguration und Nutzdaten. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/a7/52/a752b7e5080cc0ad2bcda76db111ed62/0132111650v1.jpeg "Unkontrolliert wachsende Datenbestände verursachen hohe Kosten und verhindern, Datenmehrwert freizusetzen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/22/1b/221bc534570aafc954744c039edce8a2/0131983556v1.jpeg "Mit Cloudreve lassen sich Dateien aus unterschiedlichen Speicherquellen verwalten und freigeben. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/b1/10/b110d3041f924a7a8b574498d21778f3/0131955534v2.jpeg "Schon ein begründeter Verdacht löst die NIS-2-Meldefrist aus. Wer zwischen Verdacht und Kenntnis zögert, riskiert eine persönliche Haftung der Geschäftsführung. (Bild: © Khfd - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/31/9d/319d44df4472f48e0729c4cad652387f/0132163773v1.jpeg "Wer trägt die Verantwortung? Echte Datensouveränität bei KI und Cloud bedeutet, die Kontrolle über sensible Daten sicher in der eigenen Hand zu behalten. (Bild: © Lustre - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b1/f6/b1f69d5ef82e2d28362146f1f5923060/0132433123v1.jpeg "Wasabi Technologies und Megaport haben eine strategische Partnerschaft zur Weiterentwicklung von Cloud- und KI-Infrastrukturen angekündigt. (Bild: Wasabi)")
:quality(80)/p7i.vogel.de/wcms/08/77/0877c71b77c06f4a7a94445b54db12d0/0132073799v1.jpeg "Systemcontainer und VMs gemeinsam verwalten. (Bild: Thomas Joos)")
:quality(80)/p7i.vogel.de/wcms/4f/e7/4fe7284b8da22c55a6f70fd0dee69258/0131888564v1.jpeg "Die Partnerschaft soll dazu dienen, parallelen Hochleistungszugriff mit automatisiertem Datenmanagement und skalierbarer Langzeitarchivierung für KI-, HPC- und Big-Data-Umgebungen zu kombinieren. (Bild: © Rawpixel.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4e/31/4e31cbf0807636f54ea7f6d60b7e5528/0131660732v1.jpeg "MailStore 26.2 steht ab sofort für alle Produktlinien zur Verfügung, einschließlich der Cloud-Variante und der Service Provider Edition. (Bild: MailStore)")
:quality(80)/p7i.vogel.de/wcms/fe/4e/fe4ec0867c199daba2326672ceec98ee/0132062248v1.jpeg "Ceph oder GlusterFS? Die beiden Systeme verfolgen unterschiedliche Ansätze. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/9d/30/9d30cc432198cdb72cd788af4b17aee6/0131665655v1.jpeg "RustFS ist auf Einfachheit und Effizienz ausgelegt. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c6/a3/c6a34e07c71b9c7471b09127d649cf7f/0131664925v1.jpeg "SeaweedFS wurde mit Fokus auf Einfachheit, hohe Leistung und gute Skalierbarkeit entwickelt. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/33/ef/33ef0ff6f1d27eeebb34913ccb81b127/0131664737v1.jpeg "Für seine NAS-Systeme stellt QNAP je nach Anforderungen und Einsatzgebieten zwei unterschiedliche Betriebssysteme bereit. (Bild: Gemini / KI-generiert)")
:quality(80)/images.vogel.de/vogelonline/bdb/1552300/1552323/original.jpg "Cloud-Speicher für Einsteiger – Microsoft OneDrive zusammen mit macOS und iOS nutzen. (©georgejmclittle - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1644500/1644561/original.jpg "Online-Speicher bei Web.de und GMX: So funktioniert die Verwaltung. (© stokkete - stock.adobe.com)")
:quality(80)/images.vogel.de/vogelonline/bdb/1641800/1641842/original.jpg "All-Flash-Arrays versprechen unschlagbar niedrige Latenzen. (© pozdeevvs - stock.adobe.com)")
Definition, Update: 12.7.2018 Was ist Erasure Coding?
Algorithmen zur Fehlerkorrektur bei Datenspeichern sind seit langem unverzichtbar. Einige Raid-Level kennt fast jeder, der schon mal eine Festplatte in den Händen hatte. Doch nun machen Erasure Codes dem RAID-Datenschutz seinen Platz streitig. Die Rechenleistung könnte durch Grafikkarten geliefert werden.
Anbieter zum Thema
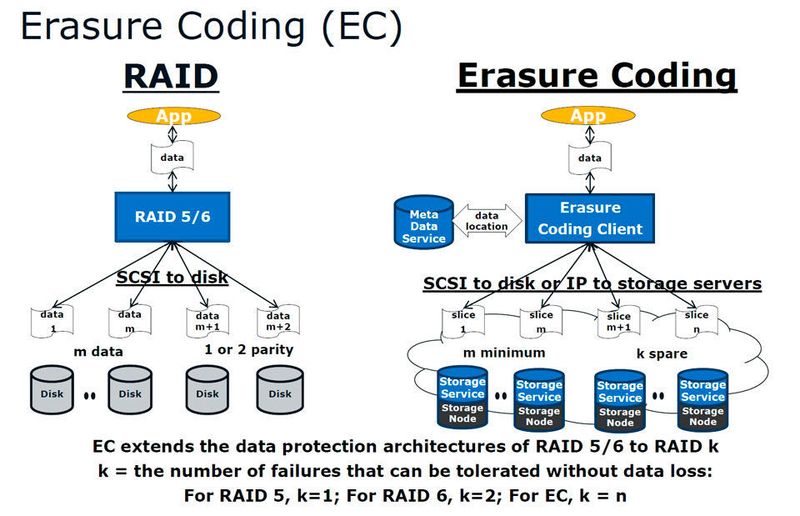
Bei Flash-Speichern redet die Industrie ungern darüber, was in einer SSD intern alles nötig ist, um die Daten "sauber" zu halten. Bei Festplatten hält fast jeder Raid für eine tolle Erfindung, doch ein weiteres Fehlerkorrekturverfahren aus der ECC-Familie (Error Correction Codes), den Erasure Codes, kennt kaum einer. Doch dieses Forward-Error-Correction-Verfahren zeigt beim Objektspeicher, dass es alles besser kann.
Objekte schicken sich an einen großen Teil der Speicherlast zu übernehmen. Noch halten aber viele ein Objekt, das durch Daten, Metadaten und eine eindeutige, globale Identifikationsnummer bestimmt ist, nur dazu fähig, fixe Daten zu speichern. Anders als bei einer Datei werden Objekte nicht überschrieben, sondern bei Änderungen in einer weiteren Version abgespeichert.
Und obwohl auch der globale Zugriff auf ein Dateisystem per CIFS und NFS möglich ist, so ist es doch wesentlich einfacher, auf ein Objekt in einer flachen Hierarchie mit http-Befehlen von jedem Ort und mit beliebigen Gerätschaften zuzugreifen.
Ein Speicher, der mit seiner Verteilung besser wird
Der Objektspeicher unterscheidet sich dahin gehend von Dateispeicher als dass er keinen Verzeichnisbaum mit Ordnern und Unterordnern besitzt. Objekte werden in einer flachen Hierarchie gespeichert, die sich mit simplen http-Befehlen wie put und get bearbeiten und speichern lassen.
Der Zugriff auf Objekte ist durch ihre Internet-kompatible Struktur über jedes Gerät mit Internetzugang erreichbar. Mittels des Indexes lassen sich die gespeicherten Identifikationsnummer und damit die Objekte respektive Objektsammlungen schnell wiederfinden.
Da der Index den Zeiger auf den tatsächlichen Ort des Dokumentes enthält, müssen Anwendungen wie auch Anwender keine Ahnung haben, wo die Datei gespeichert ist. Sie verwenden lediglich die eindeutige ID, die sich z. B. aus einer Suche in den Metadaten ergibt und das Verwaltungssystem ruft die Daten ab.
Das Objektspeichersystem ist, auch dies anders als bei einem NAS-Speichersystem, aus vielen gleichförmigen Server-Speicherknoten, die ein Grid bilden, aufgebaut, das über viele Standorte verteilt sein kann. Trotz vieler Knoten und geografischer Verteilung ist ein Objektspeicher als ein einziges logisches Speichersystem aufgebaut.
Und ein großer Vorteil der Objektspeicherung ist, dass keine dedizierte Replikations- und Backupinfrastruktur benötigt wird, um die Daten zu schützen. Möglich ist dies durch Erasure Coding, einer Technik, die verteilte und lokale Daten mit einer extrem guten Schutzwirkung vor dem Verlust von Informationen bewahrt.
Hohe Verfügbarkeit und Datenschutz passen zusammen
Obwohl Objektspeicher gerne als weitgehend ausfallsichere Archivspeicher gehandelt werden, vollzieht sich, so scheint es, aktuell ein Evolutionssprung. Es gibt bemerkenswerte Startup-Aktivitäten, die das Objekt-basierte Speichersystem mit sogenannten Gateways und Posix-Dienstprogrammen zu NAS-ähnlichem Speicher machen können. Grundlage ist wie schon beim Aufstieg der Software-gesteuerten NAS-Technik die wachsende Leistungsfähigkeit moderner Prozessoren.
Der schnelle Leistungszuwachs von x86-Prozessoren hat vor ziemlich genau dreißig Jahren für den Siegeszug von Network Attached Storage (NAS-Systemen) gesorgt und könnte nun für die breite Einführung von Objektspeichern als Ersatz für Tape und wahrscheinlich auch für das File-orientierte Speichern von Milliarden von Dokumenten sorgen.
Die der Objektspeicherung zugrunde liegenden Fehlerkorrektur-Algorithmen sind erstaunlicherweise schon über 40 Jahre alt.
Leider benötigen sie eine Rechenleistung, die erst seit wenigen Jahren auf dem benötigten Preisniveau zur Verfügung steht. Hersteller wie Fast LTA bewerkstelligen die Berechnungen inzwischen auf preiswerten Grafikkarten.
Objektspeicher erzielen viele ihrer Vorteile durch ein Bündel rechenintensiver Algorithmen, die als sogenannte Erasure Codes für Ausfallsicherheit und schnelle Wiederherstellung von Datenspeichern dienen.
Als Best Practices beim Erasure Coding gilt folgender Merksatz: Ein einzelnes Laufwerk darf nicht mehr als einen Datenblock eines Objekts aufweisen und ein einzelner Knoten darf niemals mehr Datenblöcke besitzen als das Objekt verlieren darf.
Erasure-Coding-Schutz vielfältig konstruierbar
Zwei wichtige Grundfunktionen der Objektspeicherung sind Bitspread und Geospread:
Beim Bitspread wird das Objekt auf z. B. 18 Festplatten verteilt und jeweils mit einem Error Correction Code (ECC) erweitert. Diese Fehlerkorrektur kann so gestaltet werden, dass es zu keinem Datenverlust kommt, auch wenn 5 Festplatten ausfallen würden. Die Speicherkapazität beträgt trotzdem noch 72 Prozent der Gesamtkapazität.
Beim Geospread arbeitet man mit der Verteilung des Objektes auf mehrere Standorte respektive Speichersysteme. Dabei kann z. B. ein 6/2-Erasure Code zum Einsatz kommen. Übersetzt bedeutet das, dass das Objekt auf 6 Festplatten verteilt wird, von denen 2 ausfallen könnten, ohne Datenverluste zu bewirken.
Ein Beispiel zum besseren Verständnis: Wird das Objekt nun auf drei Standorte verteilt, erhöht sich der lokale Grundschutz von 6/2 auf den erweiterten Schutz mit 18/6. Selbst bei vollständiger Zerstörung eines Speicherstandortes ließen sich alle Daten aus den beiden anderen Standorten restaurieren.
Dynamische Schutzfunktionen
Und hier kommt ein zweiter Vorteil der Erasure Codes zum Vorschein. Während der Rebuild einer 8 TByte Festplatte in einem RAID-System mehrere Tage in Anspruch nehmen würde, tragen bei der Objektspeicherung alle installierten Festplatten zur Wiedergewinnung der zerstörten Daten bei.
Erasure Codes sind nicht statisch. Auf Grund permanenter Speicherung von Daten wird im Hintergrund beständig umgeschichtet. Das bedeutet aber auch, dass Daten und ihre zugehörigen ECC-Signaturen geprüft, neu sortiert und aktualisiert werden müssen. Diese Überprüfungsroutinen erzeugen den Hauptbestandteil der Rechenlast.
Ein dritter Vorteil der Erasure Codes liegt in der Verfügbarkeit der Daten begründet. So wird von HDD-Herstellern die Zahl nicht korrigierbarer Lesefehler von guten Festplatten mit einem Fehler angegeben, wenn 10 1515 Bit gelesen worden sind. Das führt bei einem Datenbestand von einem Petabyte, das sind ca. 10 15 Byte, rein rechnerisch zu acht unkorrigierbaren Fehlern. An diesem Umstand ändert auch der Einsatz von RAID-5 oder RAID-6 nichts.
Mittels Erasure Codes lassen sich bei guter Implementierung Datenfehler in augenblicklich unwahrscheinlichste Bereiche verweisen, laut Theorie und praktischer Umsetzbarkeit liegt die Dauerhaltbarkeit eines Datums bei 15 Neunen.
(ID:44570271)
:quality(80)/p7i.vogel.de/wcms/0c/ed/0ced3344608f59ff8d8be6b73b67455b/0128862191v1.jpeg "Die Koppelung von Festplatten als RAID-Verbund soll Datenverlust beim Ausfall einzelner Platten verhindern. Zu unterscheiden ist dabei zwischen Hardware-RAID und Software-RAID. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/fe/4e/fe4ec0867c199daba2326672ceec98ee/0132062248v1.jpeg "Ceph oder GlusterFS? Die beiden Systeme verfolgen unterschiedliche Ansätze. (Bild: Gemini / KI-generiert)")